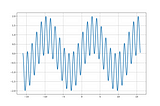
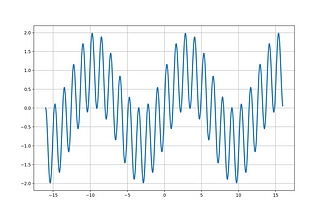
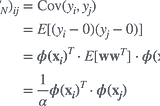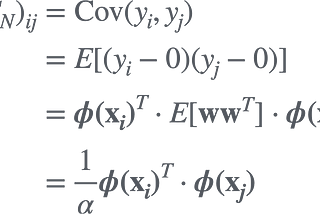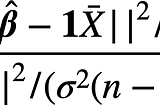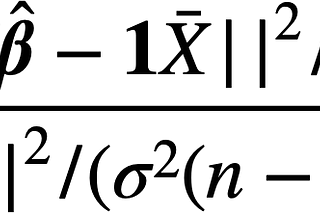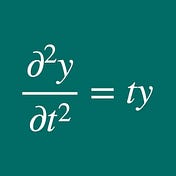T MiyamotoExample of Kalman Filter for Local Level ModelEach time a new observation is obtained for a system, the most recent infromation about the state variables is given.2 min read·Dec 29, 2023----
T MiyamotoHow to get and set a GitHub access tokenGitHub’s repository access policy has been changed since August 20212 min read·Mar 26, 2022--1--1
T MiyamotoRelation between Gaussian Process Regression and Kernel machine (short read)A simple explanation as to how Gaussian process regression is connected to Kernel machine3 min read·Feb 28, 2022----
T MiyamotoKernel method —its basicsThe basics of a kernel method is explained and a kernel function is naturally introduced.4 min read·Jan 30, 2022----
T MiyamotoMultivariate Linear RegressionExplains why t-test and F-test can be used in multivariate linear regression analysis7 min read·Dec 30, 2021----
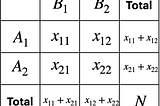
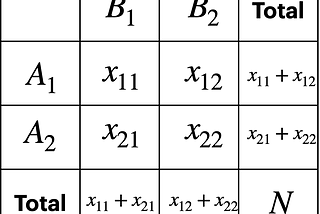
T MiyamotoIs the Covid vaccine as effective against the Omicron strain as it is against the Delta strain?We will compare the two groups using Fisher’s exact test. (Of course, the data used for the test is hypothetical.)4 min read·Nov 30, 2021----
T MiyamotoA simple guide to understand PCAThis post makes it easy to digest principal component analysis3 min read·Oct 31, 2021----
T MiyamotoA Decision Tree CodeLast year I wrote a blog article regarding decision tree. I’ve put relating code here.1 min read·Aug 31, 2021----